Git 的核心概念
文章内容来自自己的理解 和 https://git-scm.com/book/en/v2 。
本文不是Git使用教学篇,而是偏向理论方面,旨在更加深刻的理解Git,这样才能更好的使用它,让工具成为我们得力的助手。
版本控制系统
Git 是目前世界上最优秀的分布式版本控制系统。版本控制系统是能够随着时间的推进记录一系列文件的变化以便于你以后想要的退回到某个版本的系统。版本控制系统分为三大类:本地版本控制系统,集中式版本控制系统和分布式版本控制系统
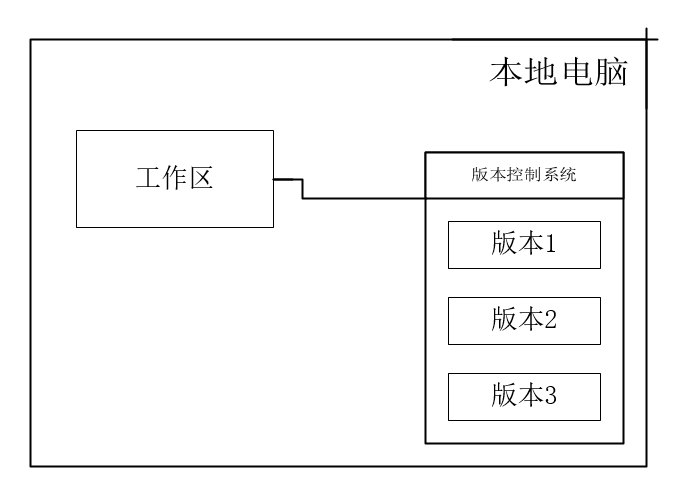
本地版本控制(Local Version Control Systems)是将文件的各个版本以一定的数据格式存储在本地的磁盘(有的VCS 是保存文件的变化补丁,即在文件内容变化时计算出差量保存起来),这种方式在一定程度上解决了手动复制粘贴的问题,但无法解决多人协作的问题。
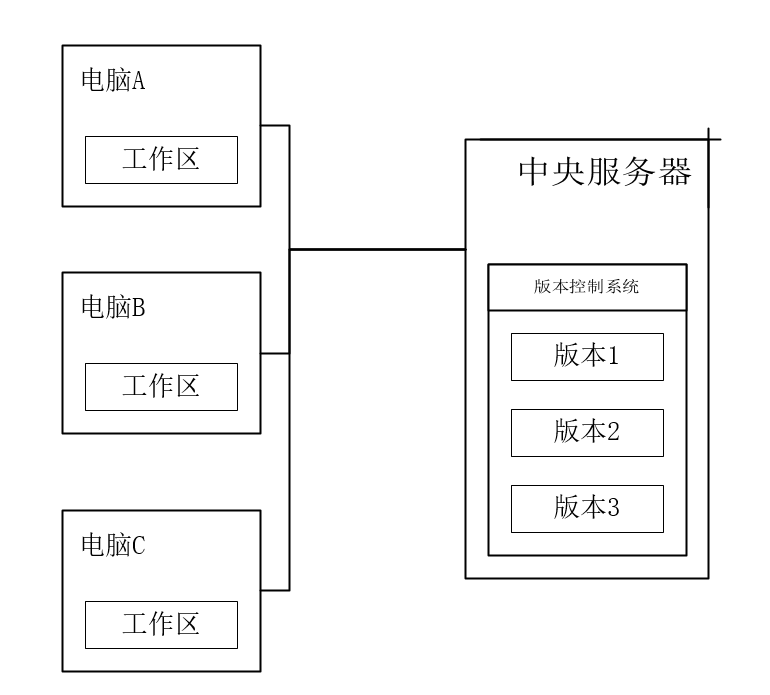
集中式版本控制(Centralized Version Control Systems)相比本地版本控制没有什么本质的变化,只是多了个一个中央服务器,各个版本的数据库存储在中央服务器,管理员可以控制开发人员的权限,而开发人员也可以从中央服务器拉取数据。集中式版本控制虽然解决了团队协作问题,但缺点也很明显:所有数据存储在中央服务器,服务器一旦宕机或者磁盘损坏,会造成不可估量的损失。
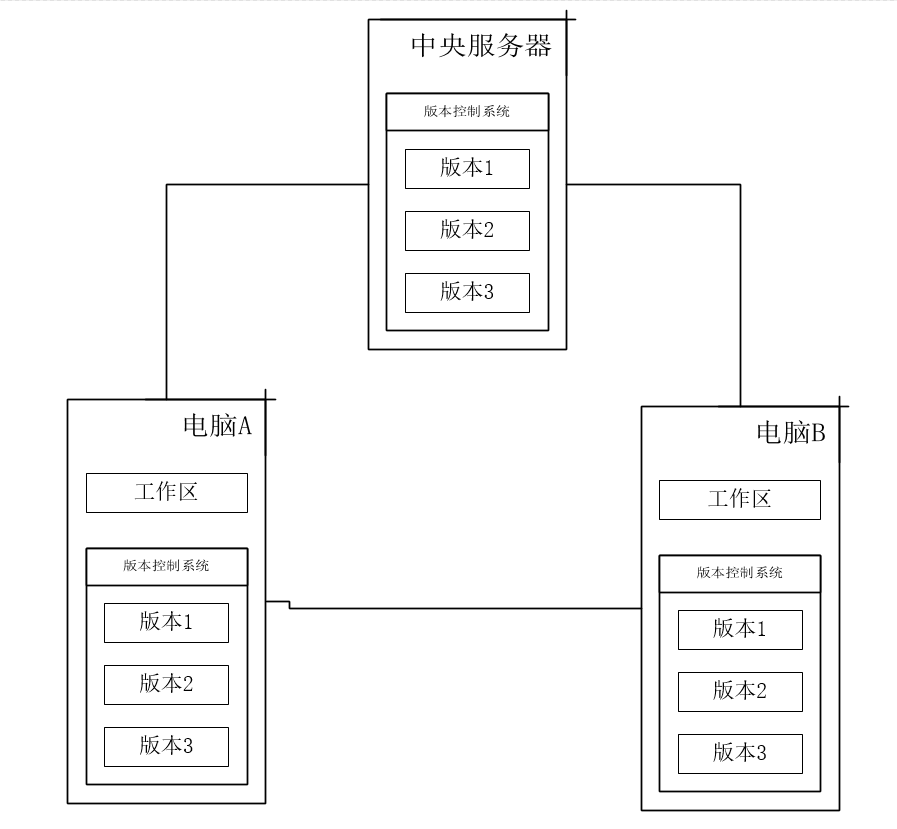
分布式版本控制( Distributed Version Control System)与前两者均不同。首先,在分布式版本控制系统中,像 Git,Mercurial,Bazaar 以及 Darcs 等,系统保存的的不是文件变化的差量,而是文件的快照,即把文件的整体复制下来保存,而不关心具体的变化内容。其次,最重要的是分布式版本控制系统是分布式的,当你从中央服务器拷贝下来代码时,你拷贝的是一个完整的版本库,包括历史纪录,提交记录等,这样即使某一台机器宕机也能找到文件的完整备份。
Git基础
Git是一个分布式版本控制系统,保存的是文件的完整快照,而不是差异变化或者文件补丁。
Git每一次提交都是对项目文件的一个完整拷贝,因此你可以完全恢复到以前的任一个提交而不会发生任何区别。这里有一个问题:如果我的项目大小是10M,那Git占用的空间是不是随着提交次数的增加线性增加呢?我提交(commit)了10次,占用空间是不是100M呢?很显然不是,Git是很智能的,如果文件没有变化,它只会保存一个指向上一个版本的文件的指针,即,对于一个特定版本的文件,Git只会保存一个副本,但可以有多个指向该文件的指针。
另外注意,Git最适合保存文本文件,事实上Git就是被设计出来就是为了保存文本文件的,像各种语言的源代码,因为Git可以对文本文件进行很好的压缩和差异分析(大家都见识过了,Git的差异分析可以精确到你添加或者删除了某个字母)。而二进制文件像视频,图片等,Git也能管理,但不能取得较好的效果(压缩比率低,不能差异分析)。实验证明,一个 500k 的文本文件经Git压缩后仅 50k 左右,稍微改变内容后两次提交,会有两个 50k 左右的文件,没错的,保存的是完整快照。而对于二进制文件,像视频,图片,压缩率非常小, Git 占用空间几乎随着提交次数线性增长。
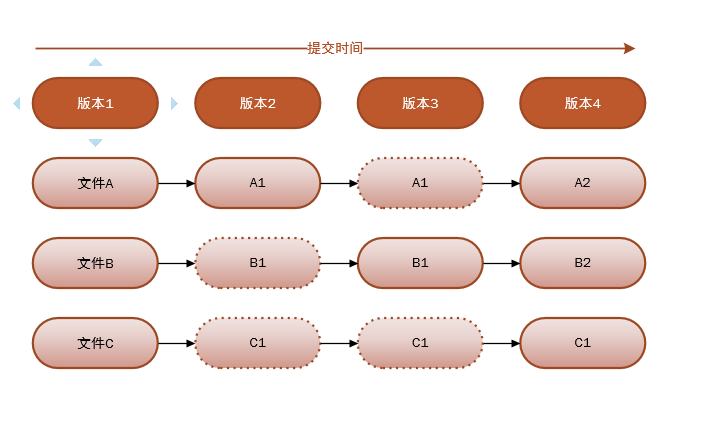
Git工程有三个工作区域:工作目录,暂存区域,以及本地仓库。工作目录是你当前进行工作的区域;暂存区域是你运行git add命令后文件保存的区域,也是下次提交将要保存的文件(注意:Git 提交实际读取的是暂存区域的内容,而与工作区域的文件无关,这也是当你修改了文件之后,如果没有添加git add到暂存区域,并不会保存到版本库的原因);本地仓库就是版本库,记录了你工程某次提交的完整状态和内容,这意味着你的数据永远不会丢失。

相应的,文件也有三种状态:已提交(committed),已修改(modified)和已暂存(staged)。已提交表示该文件已经被安全地保存在本地版本库中了;已修改表示修改了某个文件,但还没有提交保存;已暂存表示把已修改的文件放在下次提交时要保存的清单中,即暂存区域。所以使用Git的基本工作流程就是:
- 在工作区域增加,删除或者修改文件。
- 运行
git add,将文件快照保存到暂存区域。 - 提交更新,将文件永久版保存到版本库中。
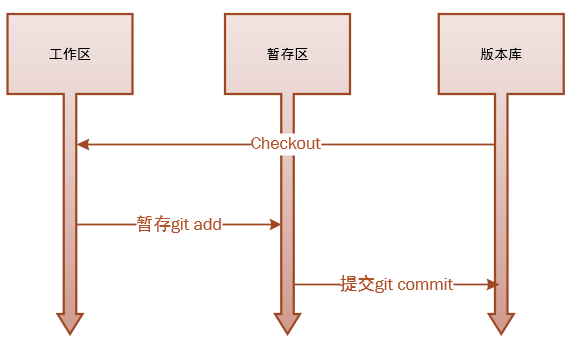
Git对象
现在已经明白Git的基本流程,但Git是怎么完成的呢?Git怎么区分文件是否发生变化?下面简单介绍一下Git的基本原理。
SHA-1 校验和
Git 是一套内容寻址文件系统。意思就是Git 从核心上来看不过是简单地存储键值对(key-value),value是文件的内容,而key是文件内容与文件头信息的 40个字符长度的 SHA-1 校验和,例如:5453545dccd33565a585ffe5f53fda3e067b84d8。Git使用该校验和不是为了加密,而是为了数据的完整性,它可以保证,在很多年后,你重新checkout某个commit时,一定是它多年前的当时的状态,完全一摸一样。当你对文件进行了哪怕一丁点儿的修改,也会计算出完全不同的 SHA-1 校验和,这种现象叫做“雪崩效应”(Avalanche effect)。
SHA-1 校验和因此就是上文提到的文件的指针,这和C语言中的指针很有些不同:C语言将数据在内存中的地址作为指针,Git将文件的 SHA-1 校验和作为指针,目的都是为了唯一区分不同的对象。但是当C语言指针指向的内存中的内容发生变化时,指针并不发生变化,但Git指针指向的文件内容发生变化时,指针也会发生变化。所以,Git中每一个版本的文件,都有一个唯一的指针指向它。
文件(blob)对象,树(tree)对象,提交(commit)对象
blob 对象保存的仅仅是文件的内容,tree 对象更像是操作系统中的目录,它可以保存blob对象和tree 对象。一个单独的 tree 对象包含一条或多条 tree 记录,每一条记录含有一个指向 blob 对象或子 tree 对象的 SHA-1 指针,并附有该对象的权限模式 (mode)、类型和文件名信息等:
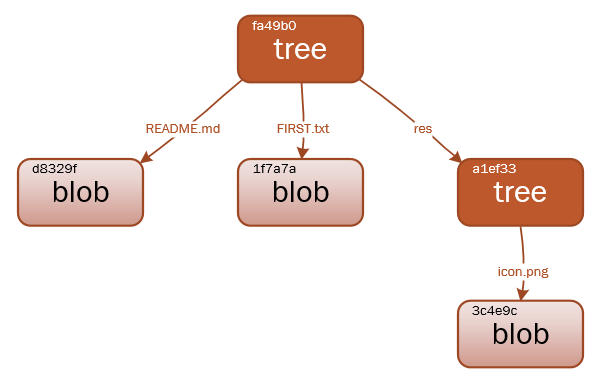 当你对文件进行修改并提交时,变化的文件会生成一个新的
当你对文件进行修改并提交时,变化的文件会生成一个新的blob对象,记录文件的完整内容(是全部内容,不是变化内容),然后针对该文件有一个唯一的 SHA-1 校验和,修改此次提交该文件的指针为该 SHA-1 校验和,而对于没有变化的文件,简单拷贝上一次版本的指针即 SHA-1 校验和,而不会生成一个全新的blob对象,这也解释了10M大小的项目进行10次提交总大小远远小于100M的原因。
另外,每次提交可能不仅仅只有一个 tree 对象,它们指明了项目的不同快照,但你必须记住所有对象的 SHA-1 校验和才能获得完整的快照,而且没有作者,何时,为什么保存这些快照的原因。commit对象就是问了解决这些问题诞生的,commit 对象的格式很简单:指明了该时间点项目快照的顶层tree对象、作者/提交者信息(从 Git 设置的 user.name 和 user.email中获得)以及当前时间戳、一个空行,上一次的提交对象的ID以及提交注释信息。你可以简单的运行git log来获取这新信息:
$ git log
commit 2cb0bb475c34a48957d18f67d0623e3304a26489
Author: lufficc <[email protected]>
Date: Sun Oct 2 17:29:30 2016 +0800
fix some font size
commit f0c8b4b31735b5e5e96e456f9b0c8d5fc7a3e68a
Author: lufficc <[email protected]>
Date: Sat Oct 1 02:55:48 2016 +0800
fix post show css
***********省略***********
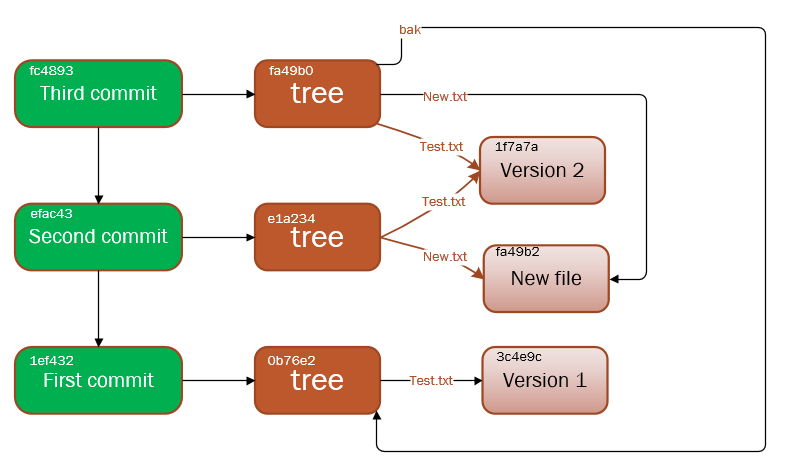
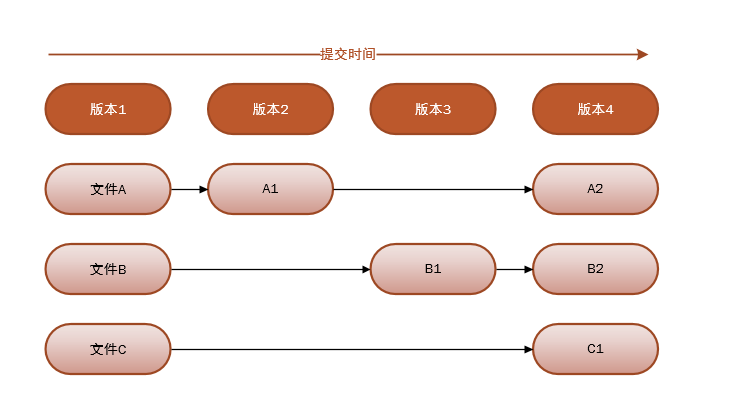
上图的Test.txt是第一次提交之前生成的,第一次它的初始 SHA-1 校验和以3c4e9c开头。随后对它进行了修改,所以第二次提交时生成了一个全新blob对象,校验和以1f7a7a开头。而第三次提交时Test.txt并没有变化,所以只是保存最近版本的 SHA-1 校验和而不生成全新的blob对象。在项目开发过程中新增加的文件在提交后都会生成一个全新的blob对象来保存它。注意除了第一次每个提交对象都有一个指向上一次提交对象的指针。
因此简单来说,blob对象保存文件的内容;tree对象类似文件夹,保存blob对象和其它tree对象;commit对象保存tree对象,提交信息,作者,邮箱以及上一次的提交对象的ID(第一次提交没有)。而Git就是通过组织和管理这些对象的状态以及复杂的关系实现的版本控制以及以及其他功能如分支。
Git引用
现在再来看引用,就会很简单了。如果我们想要看某个提交记录之前的完整历史,就必须记住这个提交ID,但提交ID是一个40位的 SHA-1 校验和,难记。所以引用就是SHA-1 校验和的别名,存储在.git/refs文件夹中。
最常见的引用也许就是master了,因为这是Git默认创建的(可以修改,但一般不修改),它始终指向你项目主分支的最后一次提交记录。如果在项目根目录运行cat .git/refs/heads,会输出一个SHA-1 校验和,例如:
$ cat .git/refs/heads/master
4f3e6a6f8c62bde818b4b3d12c8cf3af45d6dc00
因此master只是一个40位SHA-1 校验和的别名罢了。
还有一个问题,Git如何知道你当前分支的最后一次的提交ID?在.git文件夹下有一个HEAD文件,像这样:
$ cat .git/HEAD
ref: refs/heads/master
HEAD文件其实并不包含 SHA-1 值,而是一个指向当前分支的引用,内容会随着切换分支而变化,内容格式像这样:ref: refs/heads/<branch-name>。当你执行 git commit 命令时,它就创建了一个 commit 对象,把这个 commit 对象的父级设置为 HEAD 指向的引用的 SHA-1 值。
再来说说 Git 的 tag,标签。标签从某种意义上像是一个引用, 它指向一个 commit 对象而不是一个 tree,包含一个标签,一组数据,一个消息和一个commit 对象的指针。但是区别就是引用随着项目进行它的值在不断向前推进变化,但是标签不会变化——永远指向同一个 commit,仅仅是提供一个更加友好的名字。
Git分支
分支
分支是Git的杀手级特征,而且Git鼓励在工作流程中频繁使用分支与合并,哪怕一天之内进行许多次都没有关系。因为Git分支非常轻量级,不像其他的版本控制,创建分支意味着要把项目完整的拷贝一份,而Git创建分支是在瞬间完成的,而与你工程的复杂程度无关。
因为在上文中已经说到,Git保存文件的最基本的对象是blob对象,Git本质上只是一棵巨大的文件树,树的每一个节点就是blob对象,而分支只是树的一个分叉。说白了,分支就是一个有名字的引用,它包含一个提交对象的的40位校验和,所以创建分支就是向一个文件写入 41 个字节(外加一个换行符)那么简单,所以自然就快了,而且与项目的复杂程度无关。
Git的默认分支是master,存储在.git\refs\heads\master文件中,假设你在master分支运行git branch dev创建了一个名字为dev的分支,那么git所做的实际操作是:
- 在
.git\refs\heads文件夹下新建一个文件名为dev(没有扩展名)的文本文件。 - 将HEAD指向的当前分支(当前为
master)的40位SHA-1 校验和外加一个换行符写入dev文件。 - 结束。
创建分支就是这么简单,那么切换分支呢?更简单:
- 修改
.git文件下的HEAD文件为ref: refs/heads/<分支名称>。 - 按照分支指向的提交记录将工作区的文件恢复至一模一样。
- 结束。
记住,HEAD文件指向当前分支的最后一次提交,同时,它也是以当前分支再次创建一个分支时,将要写入的内容。
分支合并
再来说一说合并,首先是Fast-forward,换句话说,如果顺着一个分支走下去可以到达另一个分支的话,那么 Git 在合并两者时,只会简单地把指针右移,因为这种单线的历史分支不存在任何需要解决的分歧,所以这种合并过程可以称为快进(Fast forward)。比如:
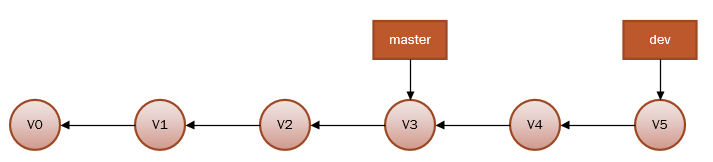
注意箭头方向,因为每一次提交都有一个指向上一次提交的指针,所以箭头方向向左,更为合理
当在master分支合并dev分支时,因为他们在一条线上,这种单线的历史分支不存在任何需要解决的分歧,所以只需要master分支指向dev分支即可,所以非常快。
当分支出现分叉时,就有可能出现冲突,而这时Git就会要求你去解决冲突,比如像下面的历史:
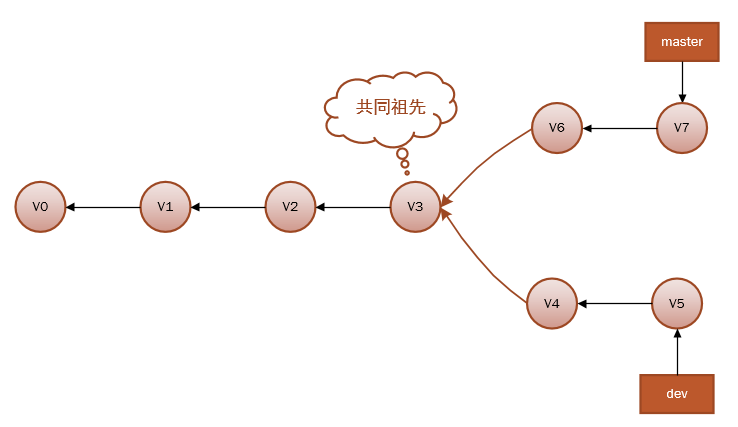
因为master分支和dev分支不在一条线上,即v7不是v5的直接祖先,Git 不得不进行一些额外处理。就此例而言,Git 会用两个分支的末端(v7 和 v5)以及它们的共同祖先(v3)进行一次简单的三方合并计算。合并之后会生成一个和并提交v8:
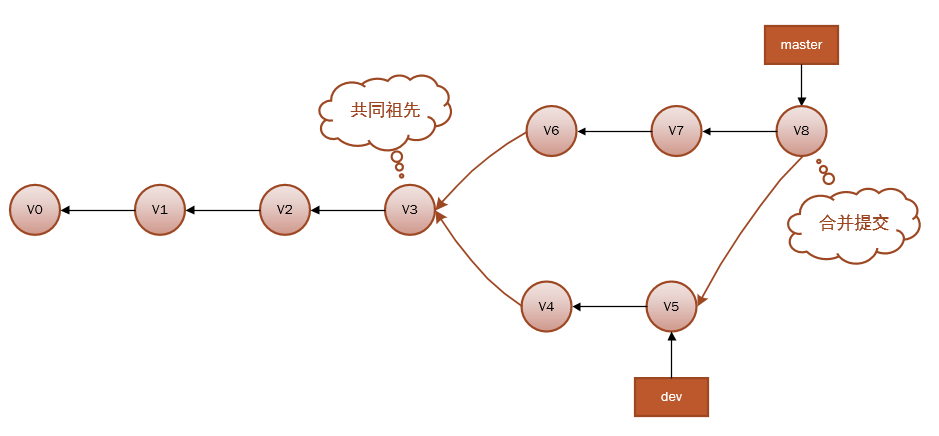
注意:和并提交有两个祖先(v7和v5)。
分支的变基rebase
把一个分支中的修改整合到另一个分支的办法有两种:merge 和 rebase。首先merge 和 rebase最终的结果是一样的,但 rebase能产生一个更为整洁的提交历史。仍然以上图为例,如果简单的merge,会生成一个提交对象v8,现在我们尝试使用变基合并分支,切换到dev:
$ git checkout dev
$ git rebase master
First, rewinding head to replay your work on top of it...
Applying: added staged command
这段代码的意思是:回到两个分支最近的共同祖先v3,根据当前分支(也就是要进行变基的分支 dev)后续的历次提交对象(包括v4,v5),生成一系列文件补丁,然后以基底分支(也就是主干分支 master)最后一个提交对象(v7)为新的出发点,逐个应用之前准备好的补丁文件,最后会生成两个新的合并提交对象(v4',v5'),从而改写 dev 的提交历史,使它成为 master 分支的直接下游,如下图:
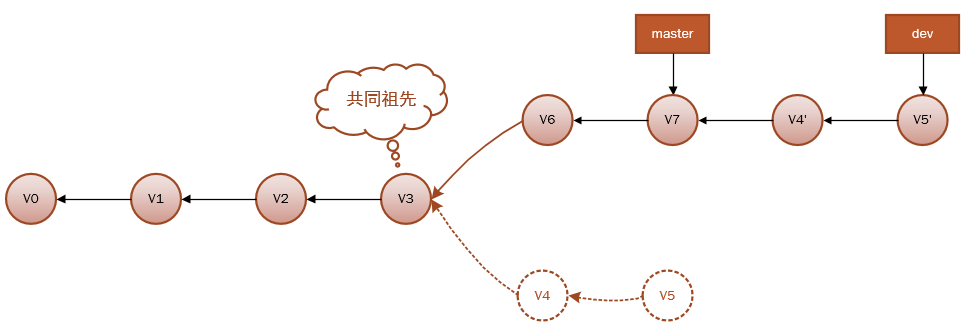
现在,就可以回到master分支进行快速合并Fast-forward了,因为master分支和dev分支在一条线上:
$ git checkout master
$ git merge dev

现在的 v5' 对应的快照,其实和普通的三方合并,即上个例子中的 v8 对应的快照内容一模一样。虽然最后整合得到的结果没有任何区别,但变基能产生一个更为整洁的提交历史。如果视察一个变基过的分支的历史记录,看起来会更清楚:仿佛所有修改都是在一根线上先后进行的,尽管实际上它们原本是同时并行发生的。
总结
- Git保存文件的完整内容,不保存差量变化。
- Git以储键值对(
key-value)的方式保存文件。 - 每一个文件,相同文件的不同版本,都有一个唯一的40位的 SHA-1 校验和与之对应。
- SHA-1 校验和是文件的指针,Git依靠它来区分文件。
- 每一个文件都会在Git的版本库里生成
blob对象来保存。 - 对于没有变化的文件,Git只会保留上一个版本的指针。
- Git实际上是通过维持复杂的文件树来实现版本控制的。
- 使用Git的工作流程基本就是就是文件在三个工作区域之间的流动。
- 应该大量使用分支进行团队协作。
- 分支只是对提交对象的一个引用。